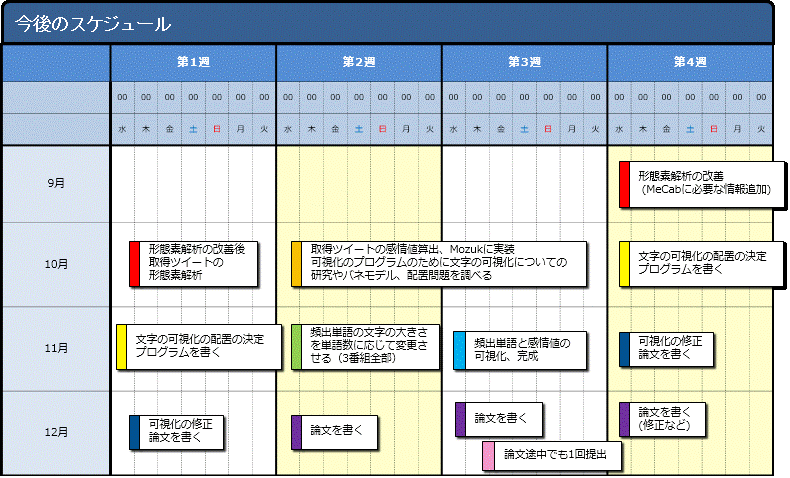
Twitterから特定のテレビ番組の実況ツイートを取得する方法とプログラムをまとめます。
開発言語はjavaとし、Twitterからツイートを取得するためにTwitter4Jを使用しました。
<参考サイト>
Twitterからつぶやきを取得する。 -放浪するエンジニアの覚え書き
Twitter4JでTweetを取得してみる
<プログラム>
- 取得したツイートをcsvファイルに書き込む
- RT、@、URL、ハッシュタグの削除
- 投稿日時、ユーザ名、本文を取得し、csvファイルには本文だけ書き込む
// 初期化
Twitter twitter = new TwitterFactory().getInstance();
Query query = new Query();
try {
File file = new File("C:\\csv\\Tweet21.csv");
PrintWriter pw = new PrintWriter(file, "Shift-JIS");
//追記で書き込む
// pw = new PrintWriter(new BufferedWriter(new FileWriter(file,true)));
DefaultTableModel tableModel = new DefaultTableModel(new String[]{"日付", "名前", "本文"}, 0);
// 検索ワードをセット
//query.setQuery("#" + txtSearchText.getText());
query.setQuery("#" +txtSearchText.getText());
// 1度のリクエストで取得するTweetの数(100が最大)
query.setCount(100);
query.setSince("2016-09-01");
query.setUntil("2016-09-10");
// 1500件(15ページ)最大数
for (int i = 1; i <= 15; i++) {
// 検索実行
QueryResult result = twitter.search(query);
System.out.println("ヒット数 : " + result.getTweets().size());
System.out.println("ページ数 : " + new Integer(i).toString());
// 検索結果を見てみる
for (Status tweet : result.getTweets()) {
// 本文
// String s = tweet.
// Dateクラスとユーザ名
String date = tweet.getCreatedAt().toString();
String user = tweet.getUser().getName();
String str = tweet.getText();
// 特定の文字の削除
str = str.replaceAll("RT", "");
// str = str.replaceAll("@", "");
if (str.charAt(1) == '@') {
int index = str.indexOf(":");
// str = str.substring(index + 1, str.length());
str = str.substring(index + 1);
}
// httpから始まるURLの削除
if (str.contains("http")) {
int index = str.indexOf("http");
str = str.substring(0, index);
// System.out.println(index + ", total = " + str.length());
}
if(str.contains("#")){
int index =str.indexOf("#");
str =str.substring(0,index);
}
if(str.contains("#")){
int index =str.indexOf("#");
str =str.substring(0,index);
}
// pw.println(date + "," + user + ",");
pw.println(str);
tableModel.addRow(new String[]{date, user, str});
// リツイート
int ret = tweet.getRetweetCount();
// ハッシュタグとURLの削除
StringTokenizer sta = new StringTokenizer(str, " ");
//トークンの出力
/* while (sta.hasMoreTokens()) {
String wk = sta.nextToken();
// if (wk.contains("http")
// && wk.contains("RT") && wk.contains("@")) {
pw.print(", ," + wk);
// }
}
*/
}
if (result.hasNext()) {
query = result.nextQuery();
} else {
break;
}
}
pw.close();
tableTweets.setModel(tableModel);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}