<目標>
文字サイズの問題・・・頻出度0の文字を表示しないようにする
文字の大きさの変化を滑らかにするために線形補間、非線形補間について勉強しながらプログラムを書きたい
<達成度>
100%
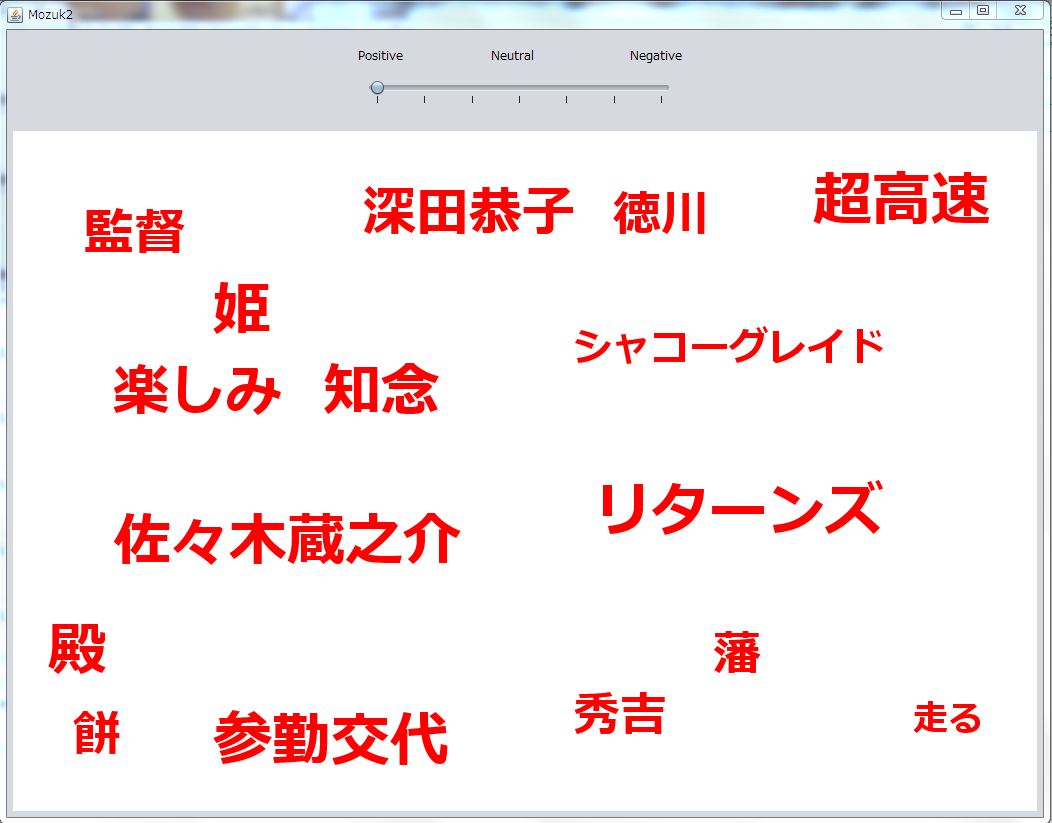
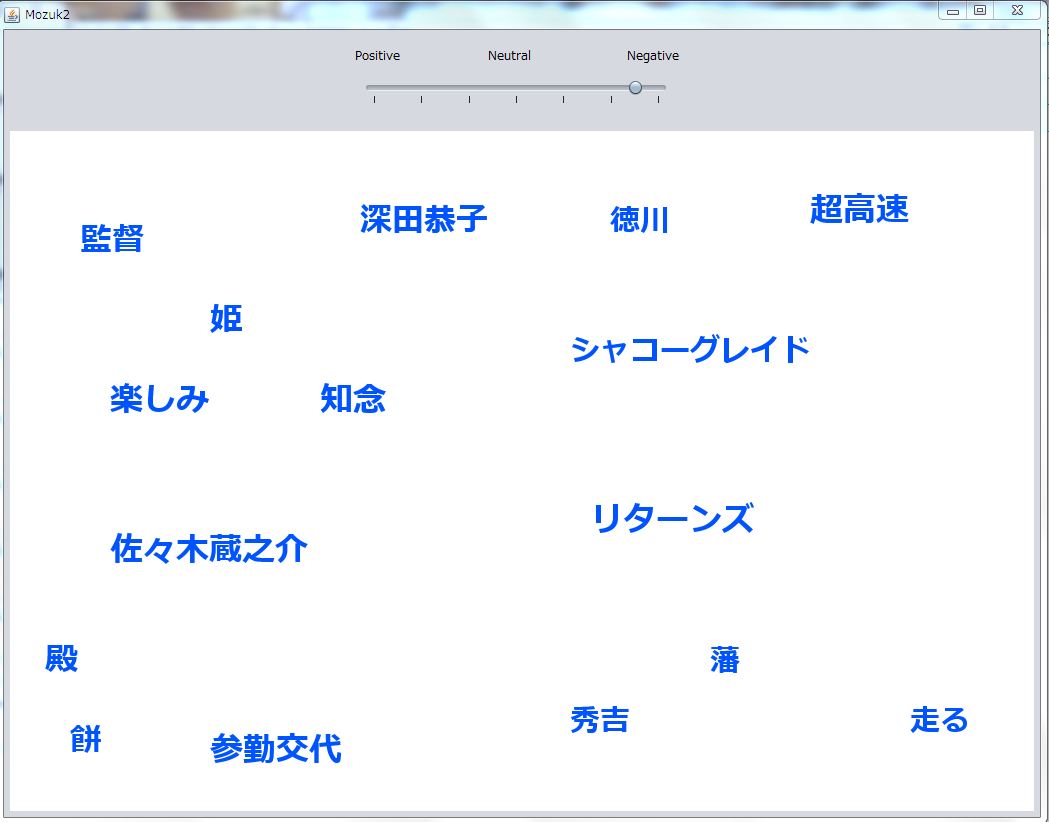
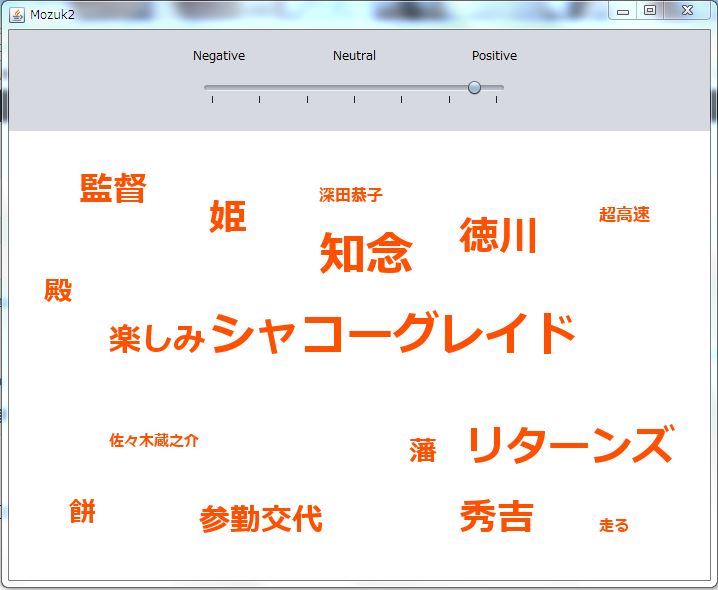
文字サイズが頻出度0の場合その文字を表示しないようにしました。
文字の大きさの変化を滑らかにするために線形補間を使って、滑らかに変化するようになりました。
<次週の目標>
文字の配置を自動になるようにする。
<活動時間>
10月20日(木)12:00~12:30,14:30~19:00@研究室 5時間
10月21日(金)15:50~19:30@研究室 3時間40分
10月25日(火)13:45~16:45@研究室 2時間
10月26日(水)12:00~18:30@研究室 3時間
合計:13時間40分
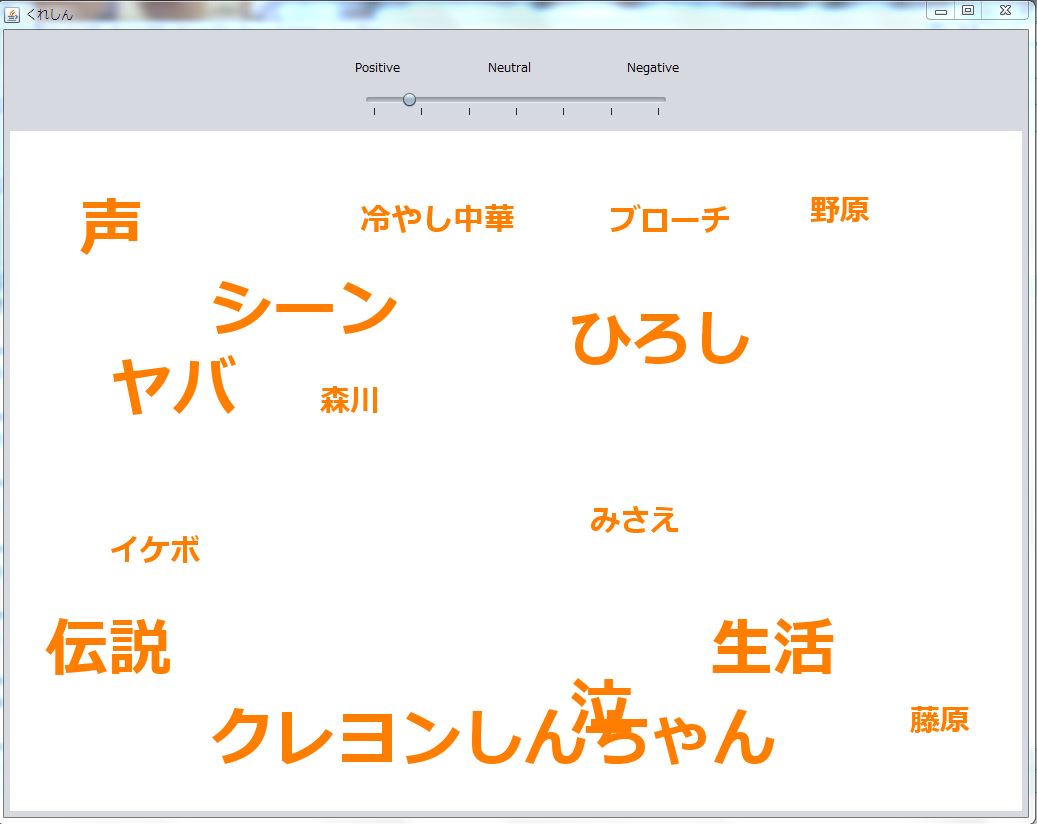
クレヨンしんちゃんの単語の「みさえ」など頻出度が0になったとき、単語を表示しないようにしました。
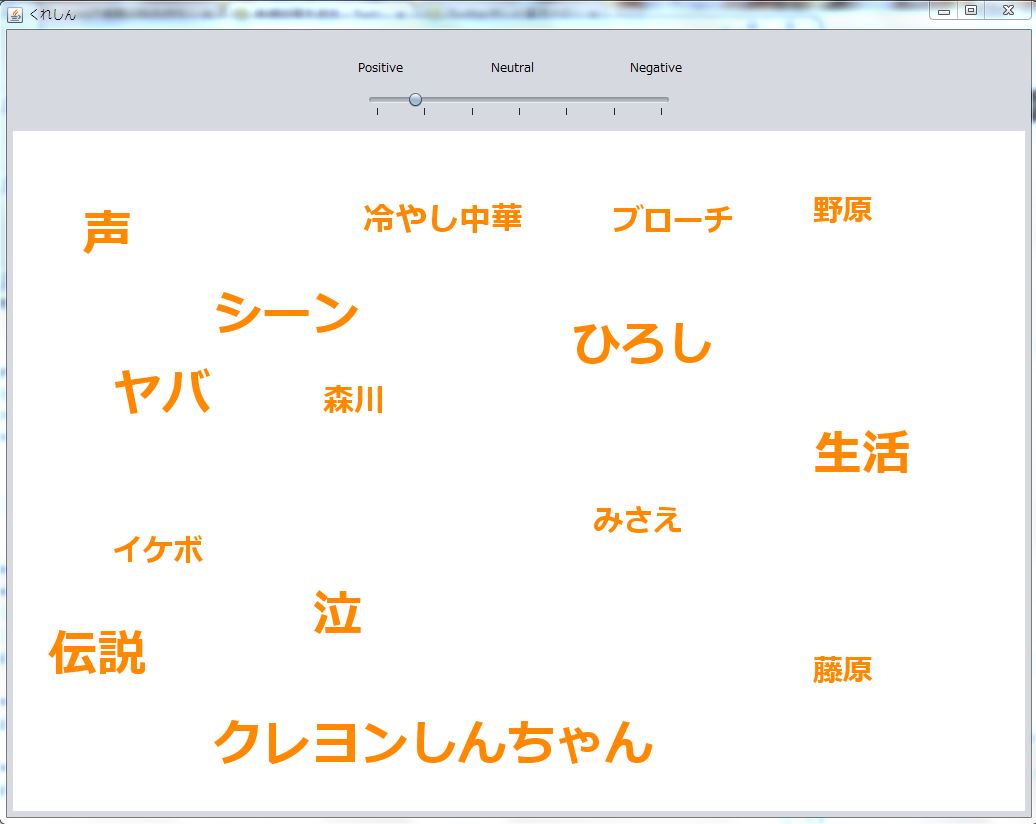
↑全単語が表示されている画面
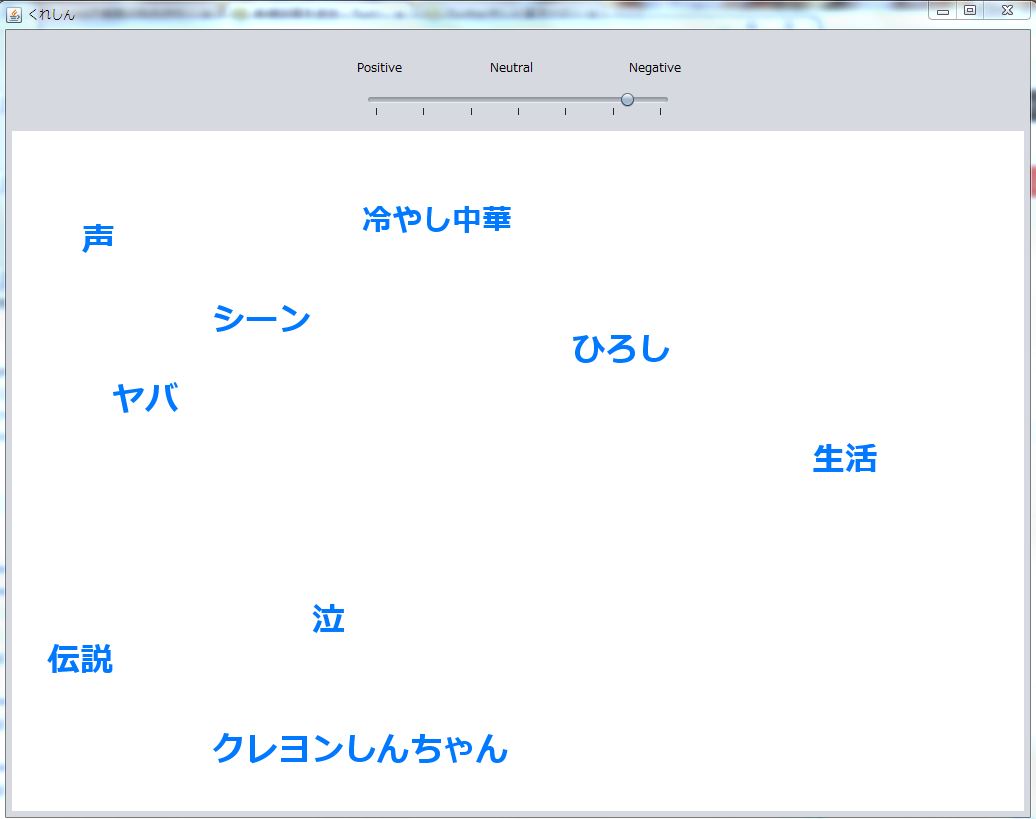
↑頻出度0の単語がある場合の画面