<目標>
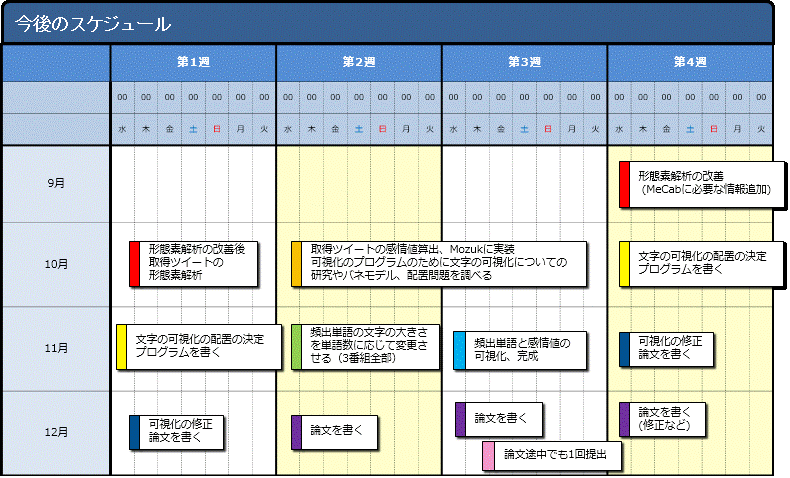
感情値のバーを移動させたら頻出単語の大きさが頻出度の数字によって変化するようにプログラムを書く
紅華祭で出せるように現在は1つの番組しか結果を反映させていないが3つの番組すべて反映させることができるように努力する
<達成度>
80%
配置の問題がまだ残っているのと、クレヨンしんちゃんの単語には頻出度0もあるのですが文字の最小のサイズを40に設定しているので文字が表示されてしまうので頻出度0の場合は文字を表示しないようにするという問題を解決できていません。
<次週の目標>
文字サイズの問題・・・頻出度0の文字を表示しないようにする
文字の大きさの変化を滑らかにするために線形補間、非線形補間について勉強しながらプログラムを書きたい
<活動時間>
10月13日(木)15:20~19:30@研究室 3時間10分
10月14日(金)14:20~14:50@研究室 30分
10月17日(月)10:00~11:50,15:00~19:00@研究室 5時間30分
10月18日(火)10:20~12:20,13:00~18:30@研究室 7時間30分
10月19日(水)13:45~18:00@研究室 3時間30分
合計:20時間10分
頻出単語のファイルを読込み、1~7の感情値ごとに頻出単語の量がどのくらい変化しているのかを表示するところまでできました。
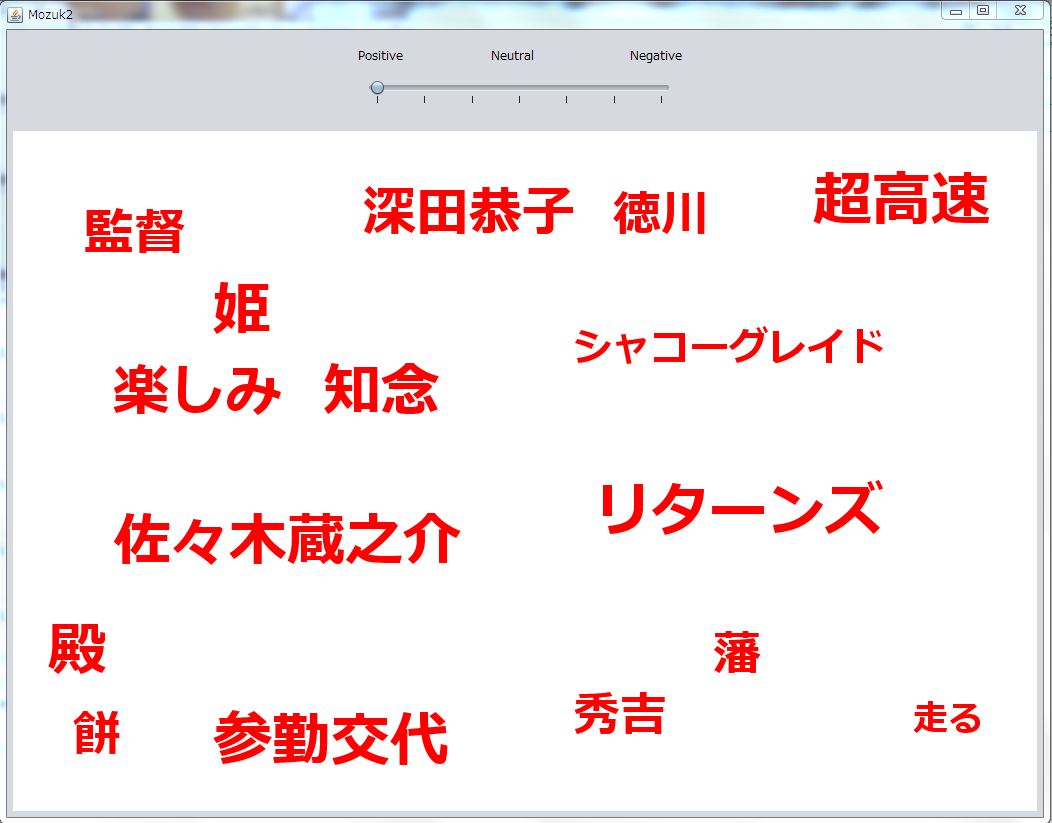
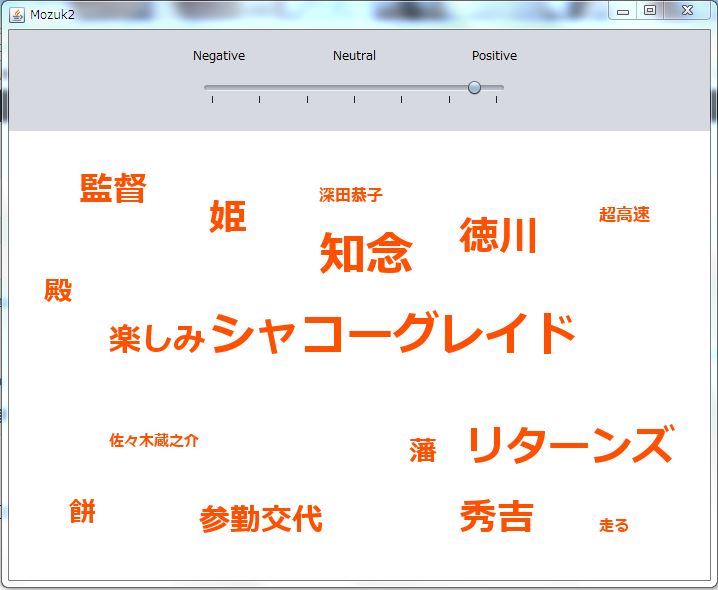
(ポジティブにバーを動かしたときの実行結果)
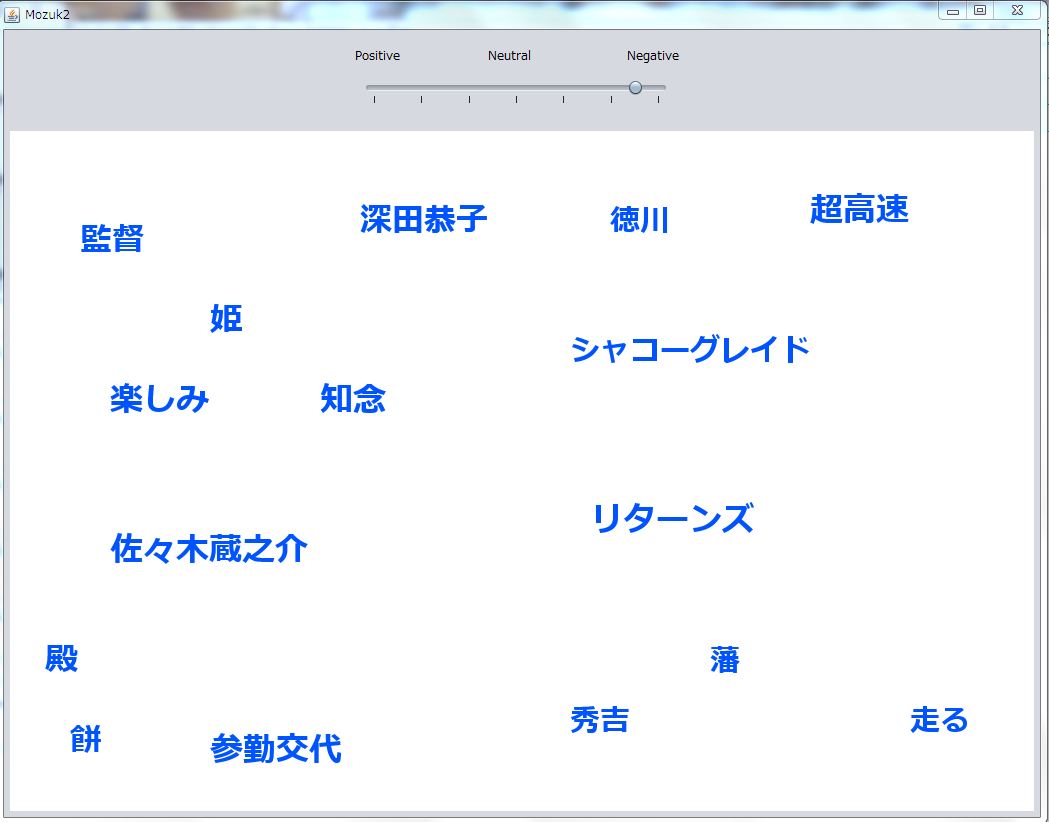
(ネガティブの方にバーを動かした実行結果)
文字のサイズが頻出度が最小の値でも見やすい大きさに変更したため餅や走るの単語が見やすくなりました。
同様にクレヨンしんちゃんのツイートも感情値算出途中のものを終わらせて、可視化してみました。
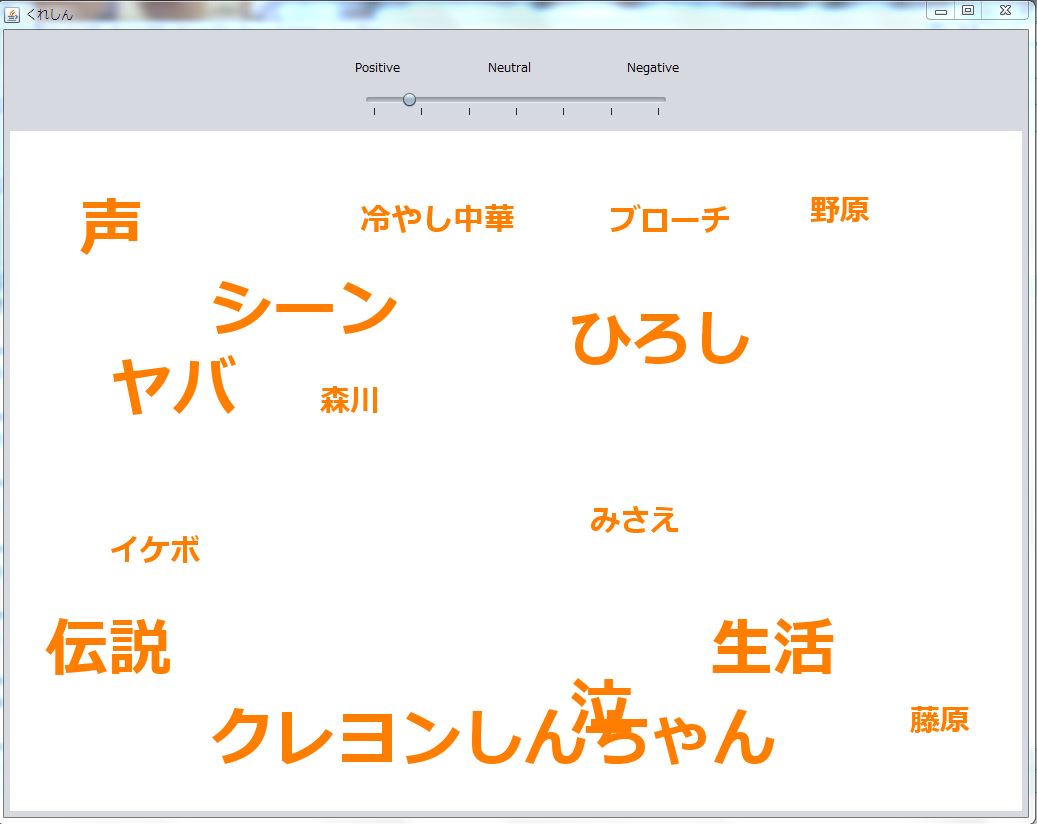
単語の表示の配置を自分で設定しているため、クレヨンしんちゃんの可視化をしたときに単語がかさなってしまいました。
やっぱり配置を自動でするように書くようにしたいと思います。。。