
作業時間:6時間くらい
内容:ポスター作成、NEologdとMeCabの比較など
月別: 2016年10月
Windowsでのmecab,Neologdのインストール
ネットでMecab、Neologdのインストール方法を調べてもWindows版があんまり出てこなかったのでここに書いておきます。
参考サイト
・64bit版Cygwinをインストールしてapt-cygするまで
・MeCab システム辞書への単語追加(mecab-ipadic-neologd)
用意するもの(Windows7)
・Cygwin
・mecab-0.996.tar.gz
・mecab-2.7.0-20070801.tar.gz
・apt-cyg(patchを入れる用)
これらをネットからどうにかして引っ張ってきてください
mecabに関してはwgetコマンド等でインストールできるものもありましたが
できないものに関しては手動でインストールして手動でフォルダに入れました。
基本的にはC:\cygwin64\usr\srcの中に入れます。
apt-cygだけC:\cygwin64\usr\local\binです。お間違えの無いようご注意。
mecabのサイトにあるmecab-0.996のパッケージでインストールされる
C:/Program Files (x86)内にできるMeCabで今まで形態素解析をしていましたがどうやらそれではだめみたい。
0.996をインストールしても途中でエラーを吐かれて萎えていました。
が、パッチがあるらしくそれを使うと0.996で行けるとの情報が。
パッケージでは辞書が含まれていましたが今回は本体のみ。
Cygwinではインストーラーで入れないと使えないコマンドが色々ありますが
進める間ずっと色んな遠回りをしたりで何を入れたか記憶にありません。必要に応じてインストールしてください。
準備として
・mecab-0.98.tar.gz
・mecab-2.7.0-20070801.tar.gz
の二つはC:/cygwin64/usr/src内に入れておく。
cygwin内でapt-cygを使えるようにしてから
apt-cyg参考サイト
patchを作ってmecabインストール
を参考に
apt-cyg install patch
を打つとpatchコマンドが使えるようになる。
srcのディレクトリに移動し
tar zxvf mecab-0.996.tar.gz tar zxvf mecab-ipadic-2.7.0-20070801.tar.gz patch -p1 -d ./mecab-0.996/ < ./mecab-0.996.patch cd ./mecab-0.996 ./configure --with-charset=utf-8 make make install cd ../mecab-ipadic-2.7.0-20070801 nkf --overwrite -Ew mecab-ipadic-2.7.0-20070801/* /usr/local/libexec/mecab/mecab-dict-index -f utf-8 -t utf-8 ./configure
patchを作ってmecabインストール
のサイトのコードと同じように見えるが辞書ファイルのインストールが違う。
neologdのコードがutf-8のみにしか対応していないのでutf-8で入れる必要があるが
なぜか辞書のほうは
./configure --with-charset=utf-8
ではutf-8でインストールされず結果文字化けしてたので注意(shift-jisだかeuc-jpになってたのに気づかず最後まで手こずった)
次にNeologdのインストール。
srcのディレクトリに移動して
git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git cd mecab-ipadic-neologd ./bin/install-mecab-ipadic-neologd xz -dkv mecab-ipadic-neologd/seed/mecab-user-dict-seed.*.csv.xz mv mecab-ipadic-neologd/seed/mecab-user-dict-seed.*.csv mecab-ipadic-2.7.0-20070801 cd mecab-ipadic-2.7.0-20070801/ /usr/local/libexec/mecab/mecab-dict-index -f utf-8 -t utf-8
まとめるとこんな感じ。Windowsだからなのかいろいろと手間がかかってしまった。
cygwinでは使えないsudoのコマンドはcygwinを管理者権限で起動するとどうにかなる。
「10日放送の「中居正広のミになる図書館」(テレビ朝日系)で、SMAPの中居正広が、篠原信一の過去の勘違いを明かす一幕があった。」の結果
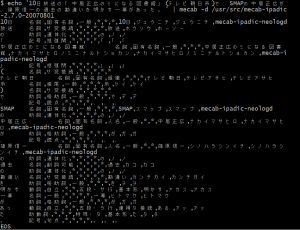
10日がトオカってならないのはなんでだろう…(不安を残す)
10月17日(月)
作業時間:8時間
内容:形態素解析に関するMecabのNeologdインストール
詳しいことはMecabのところで。
10月14日(金)
作業時間:5時間
内容:感情値拡張に伴う形態素解析ソフトの辞書変更
感情辞書拡張のためにアンケートから10単語の印象値を算出したが、
楽しい⇔悲しい
嬉しい⇔怒り
長閑⇔緊迫の3軸で取らなかったので(完全に自分のミス)
とりあえず3つの辞書全部に10単語を追加した。
ここで問題となったのが感情値を当てはめる前段階の形態素解析。
形態素解析で単語がちゃんと出てこなければ当たり前のように
感情値が出てこず形態素解析ソフトをいじる必要があった。
(例:双極性障害だと双極と性と障害とバラバラになってしまう)
感情値算出ツールで使われているのはjumanだが
算出ツールの設定で適用できるかもしれないというような話と
先生にも聞きやすいということでMeCabをいじることにした。
今回選んだ10単語をCSVファイルとしユーザー辞書として追加することを試みた。
加納先生に協力してもらったおかげで辞書ファイル化には成功したが
適用されないという問題が発生した。
MeCabで形態素解析するのにはIPAという辞書が推奨されておりそれを使っていたが
最近mecab-ipadic-neologdというWeb上の言語資源から得た新語を追加することでカスタマイズした MeCab 用のシステム辞書を入れて使っていたのでそれはどのような方法で適用されているのか調べたところこっちの辞書も適用されていないことが発覚。
neologdの大元であるGithubを見ながらインストールを試みるも
うまくいかず踏んだり蹴ったりなのが今の状況。
もはやこのページを公開して判断を仰ごうとも思ってしまっているほど
というか一体自分は何を研究しているのかわからなくなってきた。
研究テーマを辞書拡張にしたいくらい。
10月13日(木)
作業時間:3時間
内容:アンケートを元に10単語の感情値決定と統計的因果推論を読む
アンケート結果
否定的(ネガティブ)
やや否定的
どちらかと言うと否定的
どちらかと言うと肯定的
やや肯定的
肯定的(ポジティブ)
に0~5の値を振り、10単語0~5の平均値を出し、
それを5分の1することで各文の印象値を出す。
単語が含まれる文1~3文分の印象値で各単語の感情値を決定した。
明日はそれを辞書化する予定。
だが各辞書を見てみると
weight_left
weight_right
の表記が。
補正をかけるための値だと思われるがこれをどう決めるかも関わる模様。
統計的因果推論に関しては
因果に関わる
原因、結果に加えて中間特性や共変量、交絡因子というものが関わってくるそう。
本研究では
原因=過度なストレスなど
結果=精神疾患にかかる
中間特性=?
共変量=うつであるか
交絡因子=もともとストレスに弱い性格
だと思われる。多分。
今日スケジュール発表のときにある人に、
「研究に関わるツイートやその感情値を出したところで
その値が研究成果に直結するものかどうかの判断はできない」
という話、研究成果に近づけるための判断として
因果という部分を足してこの研究をやっているわけだが…終わるのか…
10月第2週
今週の目標:アンケート完成&実施
達成率:100%
作業時間:
10/6(木) 3時間
10/7(金) 3時間半
10/10(月) 3時間
10/11(火) 4時間
10/12(水) 3時間半
合計約17時間くらい
内容:10000ツイート形態素解析したものから頻度等で削っていった結果1600単語ほどになり、加納先生の力をお借りしてその1600単語から感情辞書に登録されている単語を引くプログラムを作成した。
結果40弱ほどが残り、そこからさらにアプリ連動などでつぶやかれているようなものを削った結果25単語ほどになり、そこから第一回分のアンケート用に10単語分のツイートを抜き出した。
そしてGoogleフォームを使用してアンケートを作成。
思ったよりも時間がかかり、
最初は暗い⇔明るいで行こうとしていたものを否定的⇔肯定的という風に表現したが
「分からない」という意見が殺到し単にネガポジだと思って回答してもらえるようお願いした。
回答を待つ間に「統計的因果推論」を読んではいたが、
言葉が難しく何度も読み返している状況。
今週は1600単語-感情辞書=を出すプログラムをほぼ加納先生にやってもらったが、簡単なプログラムであれば一人でも書けるよう勉強したい。
次週の目標:感情辞書の拡張
10月12日(水)
作業時間:3時間半くらい
内容:アンケート実施とスケジュール組み直しと統計的因果推論を読む(個別ゼミ2時間)
ツイートとうつの因果に対して
一度感情値を出したものを可視化
→因果推測
→それをさらに可視化
だと自分の中で思っていましたが
絶対に可視化をしないといけないわけでもないらしく
それに伴いスケジュールを変更しました。
アンケートを実施しました。
Twitter、病気の用語や否定的肯定的の判断の仕方など色々な質問が舞い込み
アンケートも難しいものだという感じです。
18時30分現在回答者が13人なのでもう少しでとりあえずの感情値が出そうです。
統計的因果推論ちょこちょこ読んではいるのですが言葉が難しくて同じところを何度も読んで理解していこうといった感じです。
個別ゼミは今後の予定やそれについてくるであろう
気苦労など色々話して終わりました
学会は出たくないです(余談)
今後のスケジュール2
研究スケジュール改訂版
今後のスケジュールを更新しました。
10月11日(火)
作業時間:4時間
内容:Googleフォームによるアンケート作成
ツイートをコピペするだけだと思っていましたが
均等目盛りにするかラジオボタンにするか
双極性障害などの用語の説明を入れないと…など
やること思ったより多くて時間がかかりました。
洋次郎や菅野さんに協力お願いして暗い明るいに関する表現の書き方や
均等目盛りではなくラジオボタンにするなど色々変更を加えてひとまずアンケートをメーリスに流しました。
10月10日(月)
作業時間:3時間
内容:アンケート作成と統計的因果推論に目を通す
アンケートは大方作成しました。
明日明後日あたり実施を予定しています。
評価の方法は0~5までの6段階評価にし、
結果の値を0~1の値に直して感情辞書にします。
統計的因果推論によると因果関係同定法には
1,一致の方法
2,付随変動の方法
3,差の方法
4,残余の方法
の4つの方法があることが分かった。