
ネットでMecab、Neologdのインストール方法を調べてもWindows版があんまり出てこなかったのでここに書いておきます。
参考サイト
・64bit版Cygwinをインストールしてapt-cygするまで
・MeCab システム辞書への単語追加(mecab-ipadic-neologd)
用意するもの(Windows7)
・Cygwin
・mecab-0.996.tar.gz
・mecab-2.7.0-20070801.tar.gz
・apt-cyg(patchを入れる用)
これらをネットからどうにかして引っ張ってきてください
mecabに関してはwgetコマンド等でインストールできるものもありましたが
できないものに関しては手動でインストールして手動でフォルダに入れました。
基本的にはC:\cygwin64\usr\srcの中に入れます。
apt-cygだけC:\cygwin64\usr\local\binです。お間違えの無いようご注意。
mecabのサイトにあるmecab-0.996のパッケージでインストールされる
C:/Program Files (x86)内にできるMeCabで今まで形態素解析をしていましたがどうやらそれではだめみたい。
0.996をインストールしても途中でエラーを吐かれて萎えていました。
が、パッチがあるらしくそれを使うと0.996で行けるとの情報が。
パッケージでは辞書が含まれていましたが今回は本体のみ。
Cygwinではインストーラーで入れないと使えないコマンドが色々ありますが
進める間ずっと色んな遠回りをしたりで何を入れたか記憶にありません。必要に応じてインストールしてください。
準備として
・mecab-0.98.tar.gz
・mecab-2.7.0-20070801.tar.gz
の二つはC:/cygwin64/usr/src内に入れておく。
cygwin内でapt-cygを使えるようにしてから
apt-cyg参考サイト
patchを作ってmecabインストール
を参考に
apt-cyg install patch
を打つとpatchコマンドが使えるようになる。
srcのディレクトリに移動し
tar zxvf mecab-0.996.tar.gz tar zxvf mecab-ipadic-2.7.0-20070801.tar.gz patch -p1 -d ./mecab-0.996/ < ./mecab-0.996.patch cd ./mecab-0.996 ./configure --with-charset=utf-8 make make install cd ../mecab-ipadic-2.7.0-20070801 nkf --overwrite -Ew mecab-ipadic-2.7.0-20070801/* /usr/local/libexec/mecab/mecab-dict-index -f utf-8 -t utf-8 ./configure
patchを作ってmecabインストール
のサイトのコードと同じように見えるが辞書ファイルのインストールが違う。
neologdのコードがutf-8のみにしか対応していないのでutf-8で入れる必要があるが
なぜか辞書のほうは
./configure --with-charset=utf-8
ではutf-8でインストールされず結果文字化けしてたので注意(shift-jisだかeuc-jpになってたのに気づかず最後まで手こずった)
次にNeologdのインストール。
srcのディレクトリに移動して
git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git cd mecab-ipadic-neologd ./bin/install-mecab-ipadic-neologd xz -dkv mecab-ipadic-neologd/seed/mecab-user-dict-seed.*.csv.xz mv mecab-ipadic-neologd/seed/mecab-user-dict-seed.*.csv mecab-ipadic-2.7.0-20070801 cd mecab-ipadic-2.7.0-20070801/ /usr/local/libexec/mecab/mecab-dict-index -f utf-8 -t utf-8
まとめるとこんな感じ。Windowsだからなのかいろいろと手間がかかってしまった。
cygwinでは使えないsudoのコマンドはcygwinを管理者権限で起動するとどうにかなる。
「10日放送の「中居正広のミになる図書館」(テレビ朝日系)で、SMAPの中居正広が、篠原信一の過去の勘違いを明かす一幕があった。」の結果
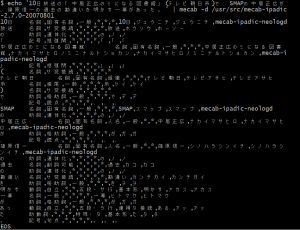
10日がトオカってならないのはなんでだろう…(不安を残す)